Heterogeneous data - a challenge for data science
Karolina Worf
wrote on
Data - the building block of everything
What can no company or research project live without these days? That’s right, DATA!
Data comes in different forms, varieties and sizes. Nowadays, we often talk about Big Data: large and very complex datasets that can no longer be easily processed manually. Data Science is concerned with analyzing precisely these large datasets to uncover the information hidden. The enormous amount of Big Data that is generated every day leaves an immense unused potential, especially in the biological and medical field.
One of the challenges in Data Science is the variety of data sources. Often different software is used to generate and collect data, resulting in heterogeneous datasets that must first be linked and/or translated for further use. This data preprocessing and cleaning is very time-consuming and costly and is even enhanced by the increase of emerging – data generating – technologies.
The heterogeneity of biomedical data originates from the complexity of nature itself!
The everyday life of a data scientist: where to start?
Which marker is a disease biomarker? Which signaling pathways are deregulated in a disease? Answering these and many other questions are central tasks of scientists in biotechnology.
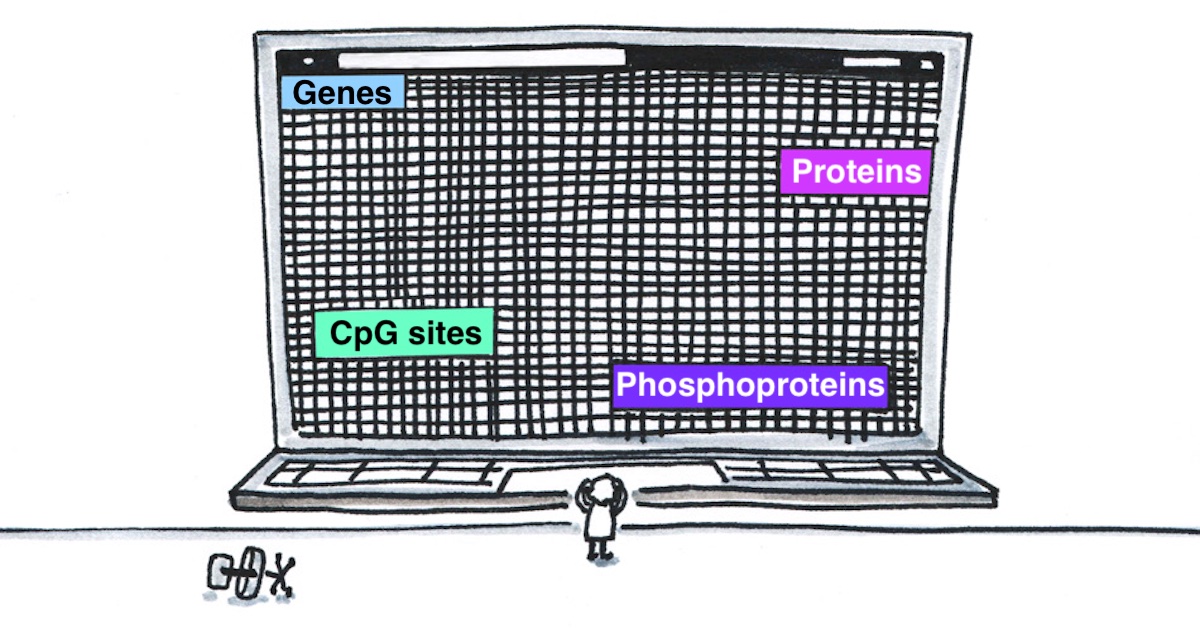
Unfortunately, linking multiple OMICs and heterogeneous data types, a process known as multiOMICs analysis, is not as trivial as it might seem (Read more about the OMICs data here). Moreover, Data Science, especially multiOMICs analysis, is a relatively new field. It can be difficult to find someone with the necessary expertise, and analyzing the data itself can be an overwhelming task for many researchers. In the end, the question often arises: where do I start?
The cumbersome way of data integration
Many scientists simply start their projects from scratch. Even though it’s one way to start a project, it may also be a hindrance. Since it is cumbersome to compare one’s data to other datasets, a data scientist can only focus on a small set. Thus, the data is not put into context by all possible means. This also happens due to a lack of suitable software tools.
A unified (bio-) data model could be the solution. It contains publicly available datasets into which scientists can integrate their own data, saving a lot of time and effort. Wouldn’t it be nice if such a model existed? knowing01’s CellMap technology is exactly this and more!
Do you want to learn more about knowing01’s CellMap technology – our dictionary of life – or how we can help you unlock the value of your data assets? Then book a meeting with us or use the contact form below.